Resource
| Id | pipeline/hg38_autism_annotation |
|---|---|
| Type | annotation_pipeline |
| Version | 0 |
| Summary |
Autism Annotation Pipeline
|
| Description |
This is a pipeline to annotate with autism related attributes. |
| Labels |
Pipeline Documentation
preamble
| Summary | Autism Annotation Pipeline for hg38 |
|---|---|
| Description | This is a pipeline to annotate variants in hg38 assembly with autism related attributes. |
| Input reference genome | hg38/genomes/ucsc-hg38 |
Annotators
Worst effect across all transcripts.
<gene_1>:<effect_1>|... A gene can be repeated.
Effect details for each affected transcript. Format: < transcript 1 >:<gene 1>:<effect 1>:<details 1>|...
List of all genes
Annotator to identify the effect of the variant on protein coding.
Worst effect across all transcripts.
Effect details for each affected transcript. Format: < transcript 1 >:<gene 1>:<effect 1>:<details 1>|...
<gene_1>:<effect_1>|... A gene can be repeated.
Annotator to identify the effect of the variant on protein coding.
Normalized allele.
dbSNP ID (i.e. rs number)
allele_aggregator: list
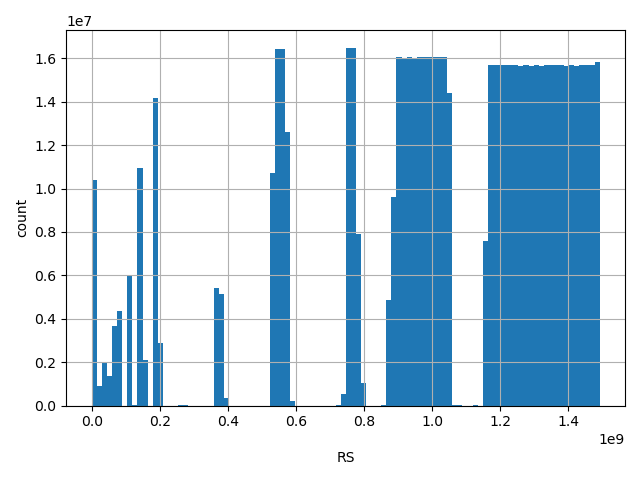
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
- input_annotatable:
normalized_allele
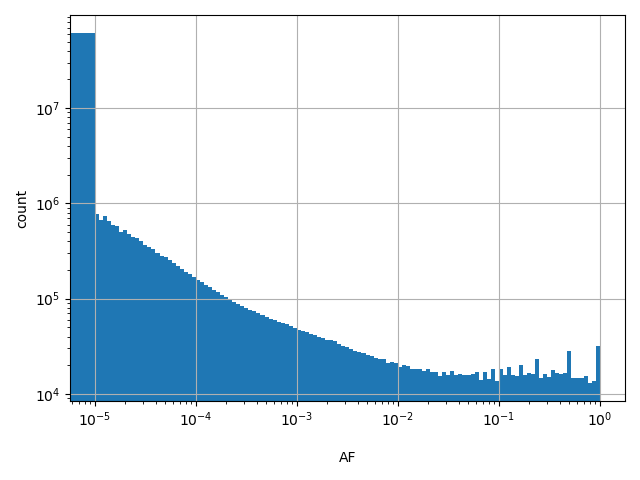
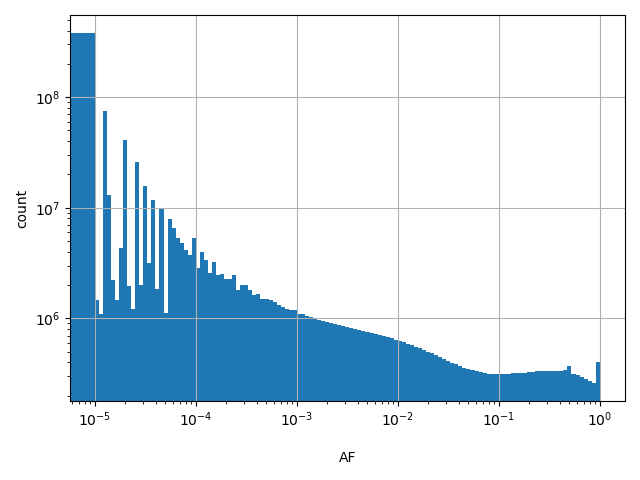
Alternate allele frequency
allele_aggregator: max
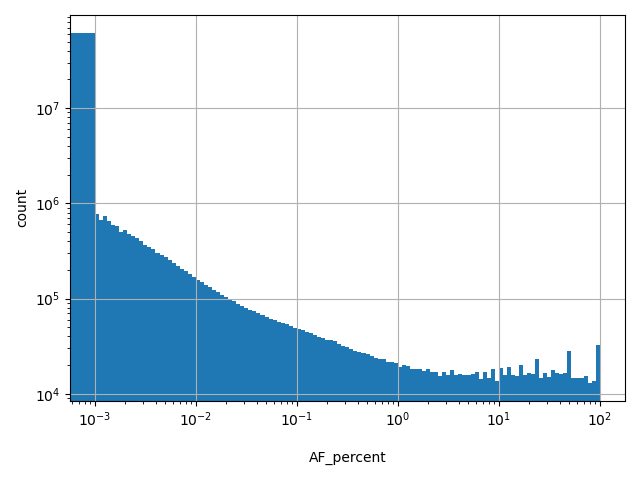
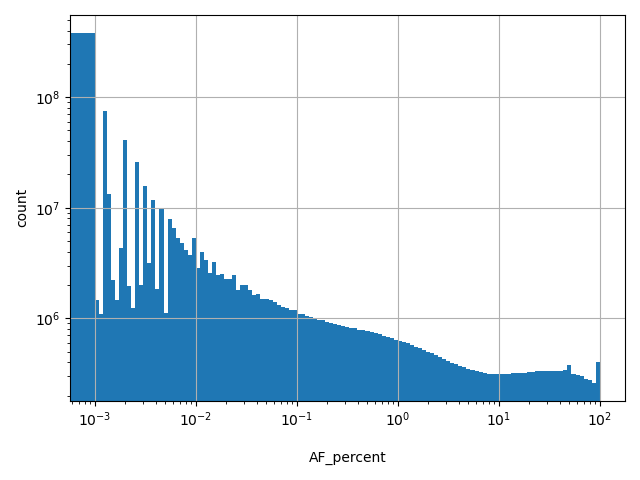
Alternate allele frequency as percent
allele_aggregator: max
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
- input_annotatable:
normalized_allele
Alternate allele frequency
allele_aggregator: max
Alternate allele frequency as percent
allele_aggregator: max
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
- input_annotatable:
normalized_allele
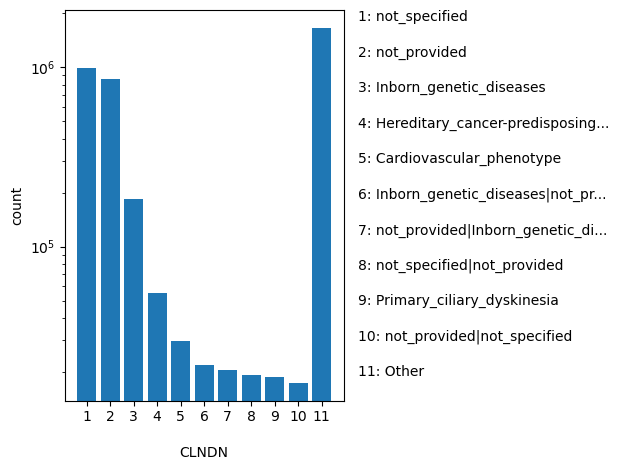
ClinVar's preferred disease name for the concept specified by disease identifiers in CLNDISDB
allele_aggregator: list
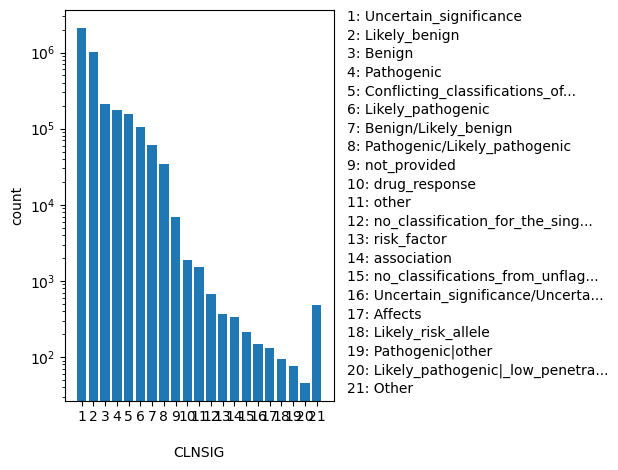
Aggregate germline classification for this single variant; multiple values are separated by a vertical bar
allele_aggregator: list
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
- input_annotatable:
normalized_allele
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
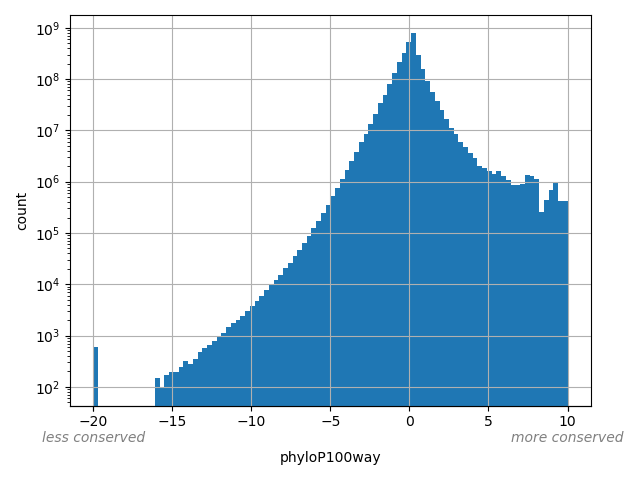
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
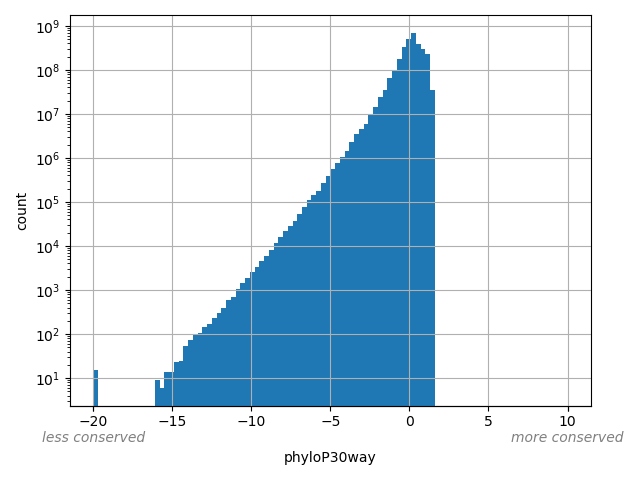
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
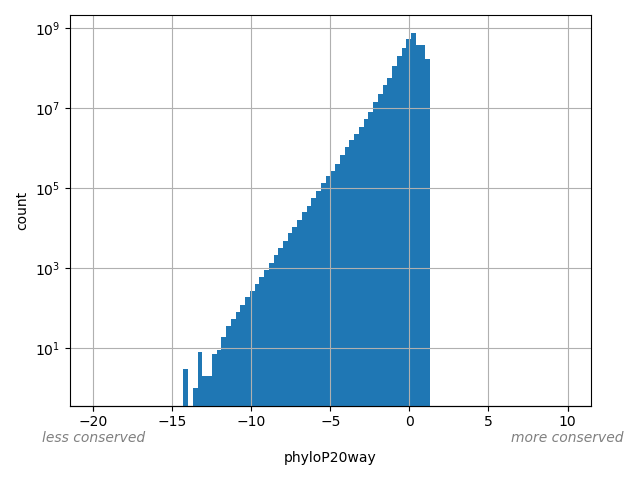
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
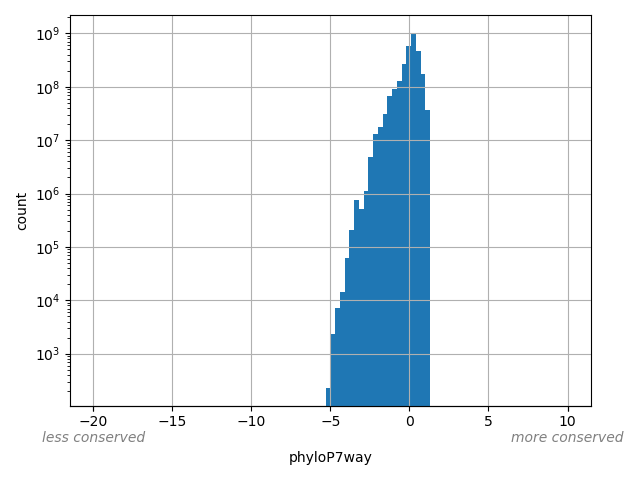
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
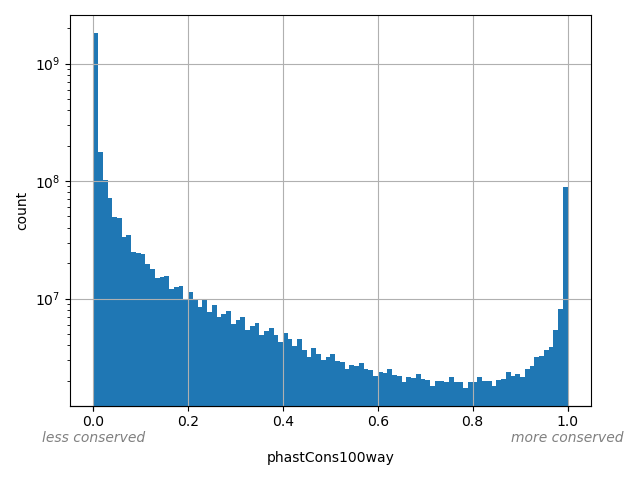
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]

Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
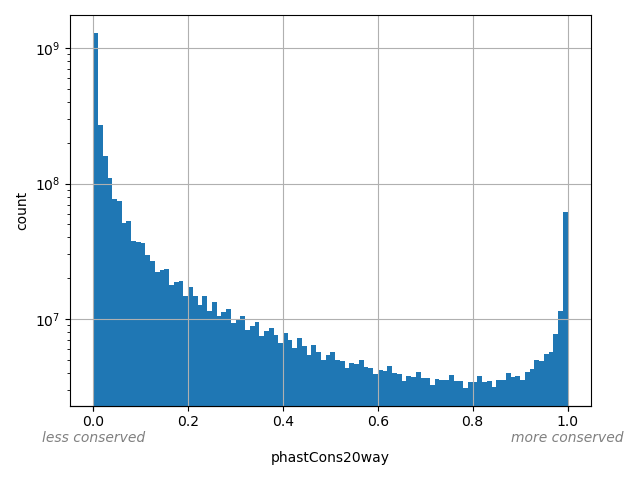
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
The score is a number that reflects the conservation at a position.
position_aggregator: mean [default]
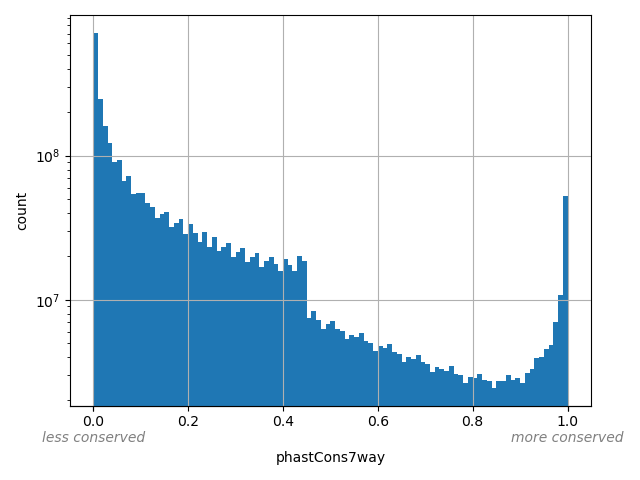
Annotator to use with genomic scores depending on genomic position like phastCons, phyloP, FitCons2, etc.
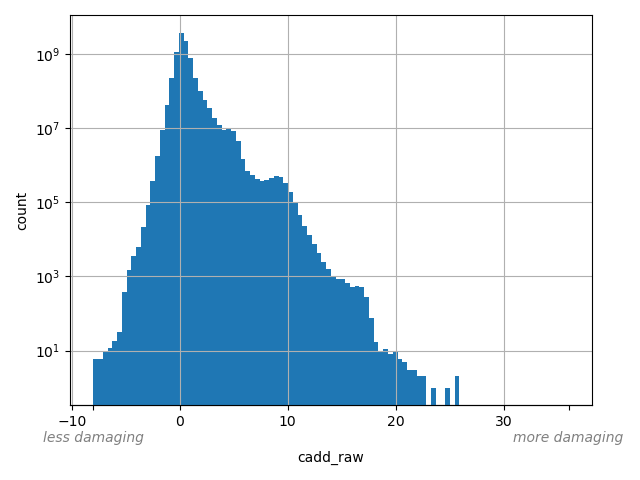
CADD raw score for functional prediction of a SNP. The larger the score the more likely the SNP has damaging effect
allele_aggregator: max
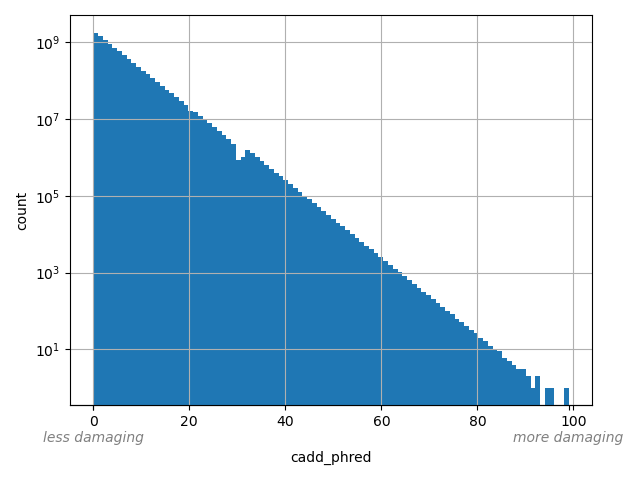
CADD phred-like score. This is phred-like rank score based on whole genome CADD raw scores. The larger the score the more likely the SNP has damaging effect.
allele_aggregator: max
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
AlphaMissense Pathogenicity score is a deleteriousness score for missense variants
allele_aggregator: max
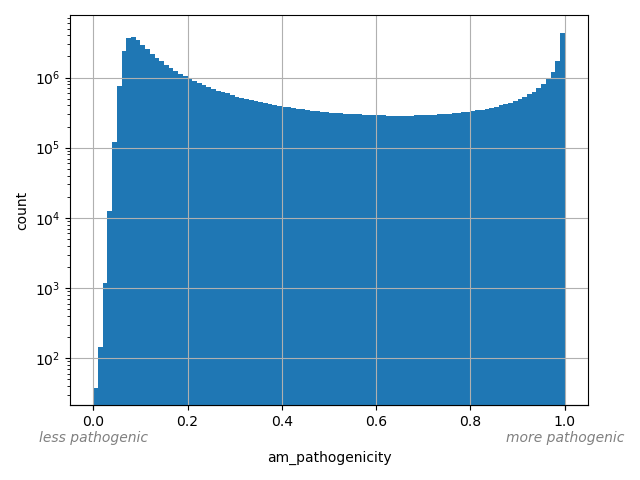
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
The lifted over annotatable
Annotator to lift over a variant from one reference genome to another.
Missense badness, PolyPhen-2, and Constraint. A deleteriousness prediction score for missense variants"
allele_aggregator: max
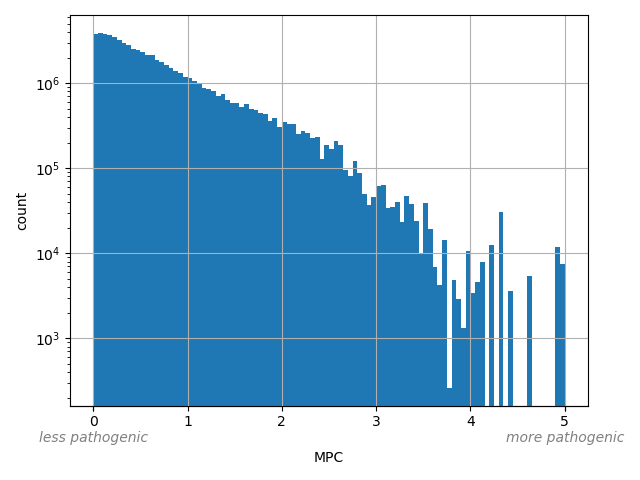
Annotator to use with scores that depend on allele like variant frequencies, etc.
Mode (mode parameter, applies to VCFAllele inputs only):
allele(default): exact chrom/pos/ref/alt match.region: aggregates scores for all allele lines overlapping the annotatable's span.
Non-VCFAllele annotatables always use region aggregation.
- input_annotatable:
hg19_annotatable
Gene rank after sorting by pLI intolerance score
Gene rank after sorting by pLI intolerance score
Gene ranks after sorting by LOEUF scores
Gene ranks after sorting by LOEUF scores
Multiple hypothesis adjusted p-value for gene-autism association
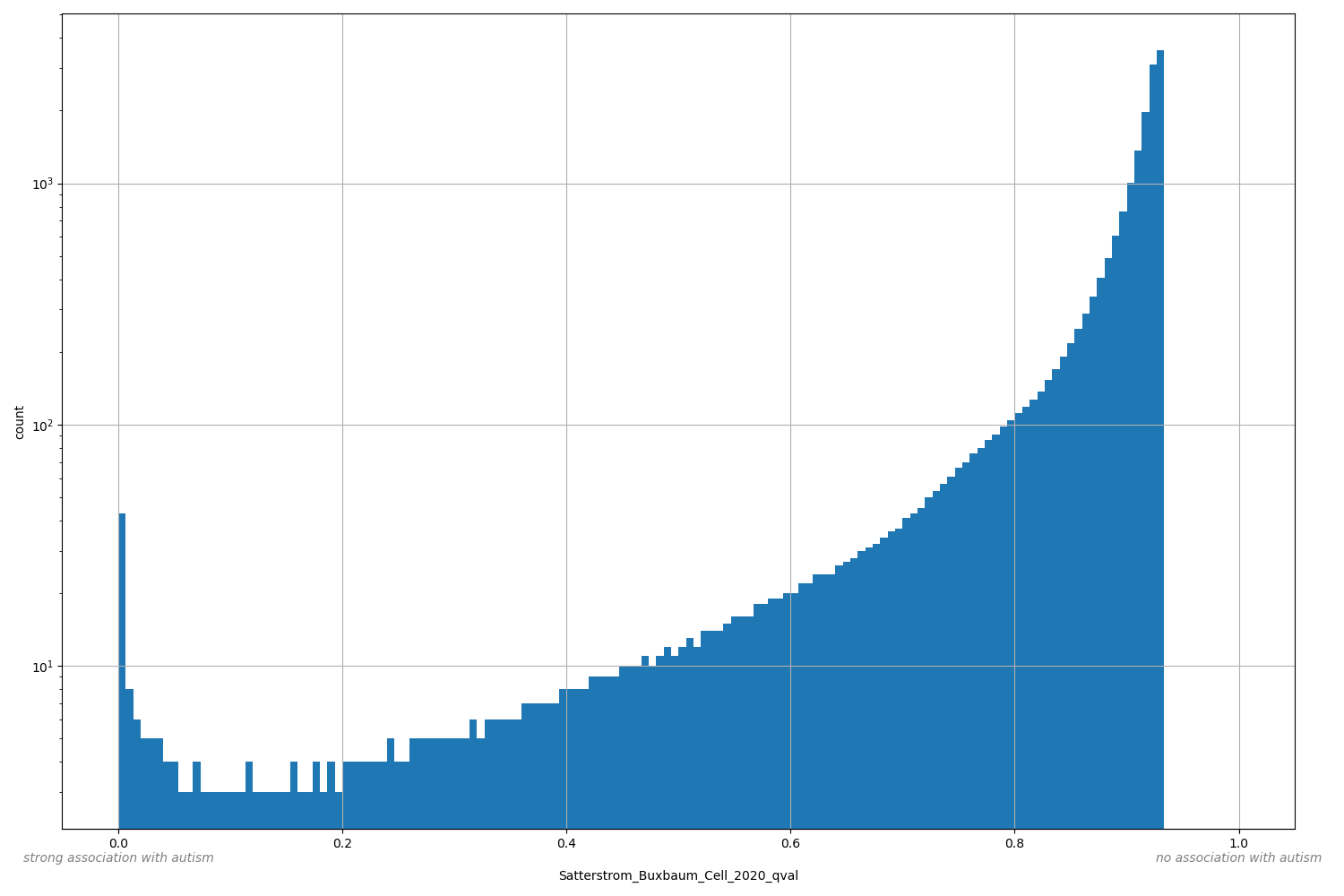
Probability of a gene to be associated with autism
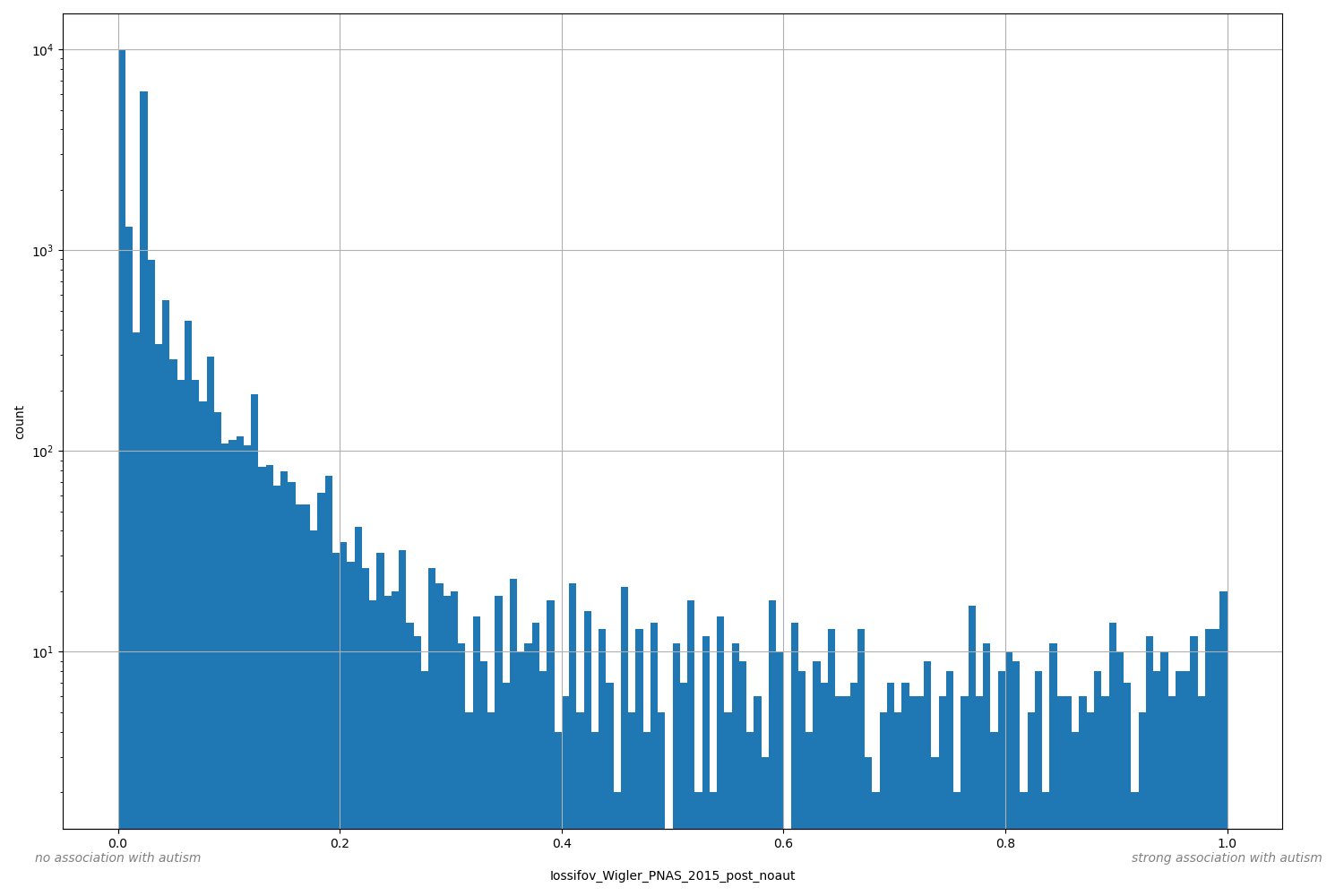
Evidence strength supporting a gene's association with autism
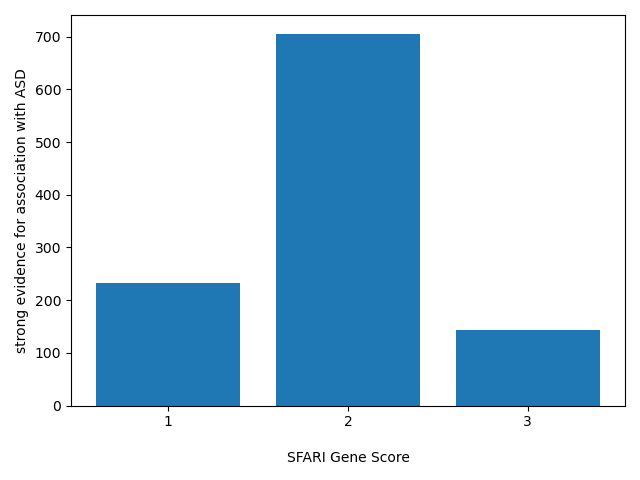
(239) Iossifov I., et al. Low load for disruptive mutations in autism genes and their biased transmission. PNAS (2015)
(65) Sanders S., et. al, Insights into Autism Spectrum Disorder Genomic Architecture and Biology from 71 Risk Loci. Neuron (2015)
(55) List of genes (unique) from paper YuenSchererNature2017NEW, Supplementary Table 5. All damaging variants in ASD-risk genes.
(52) List of genes from paper TurnerEichlerajhg2019, Supplementary mmc2 Excel file, Sheet: TableS5
(102) List of genes (unique) from paper SatterstromBuxbaumCell_2020, Supplementary mmc2 Excel file, Sheet: 102 ASD
This gene set collection annotator uses the autism gene set collection.
The number of CNVs overlapping with the annotatable.
The number of CNVs overlapping with the annotatable.
The number of CNVs overlapping with the annotatable.
Files
| Filename | Size | md5 |
|---|---|---|
| genomic_resource.yaml | 204.0 B | d2798b17ff4fb927fe4528f2ce48eeec |
| hg38_autism_annotation.yaml | 4.29 KB | deb9a282613b6b66ea54e64cfb26f29e |
| statistics/ |